Τι είναι το Web Scraping και πώς λειτουργεί στον ψηφιακό κόσμο
Τα δεδομένα(Data) και οι πληροφορίες είναι δύο όροι που χρησιμοποιούνται συχνά εναλλακτικά, αλλά υπάρχει μια αξιοσημείωτη διαφορά μεταξύ τους. Για παράδειγμα, τα δεδομένα αναφέρονται σε κομμάτια πληροφοριών, αλλά όχι σε πληροφορίες. Από την άλλη πλευρά, οι πληροφορίες(Information) είναι ένα σύνολο δεδομένων που υποβάλλονται σε επεξεργασία με ουσιαστικό τρόπο. Με τα συντριπτικά δεδομένα που είναι διαθέσιμα στο Διαδίκτυο, χρησιμοποιούνται διαφορετικές προσεγγίσεις όπως το Web Scraping , το Web Harvesting ή η Web Data Extraction για τη δημιουργία πρακτικών και εναλλασσόμενων πληροφοριών σχετικά με τη χρήση του Διαδικτύου(Internet) . Αλλά τι ακριβώς σημαίνουν στον διαδικτυακό κόσμο. Ας ΡΙΞΟΥΜΕ μια ΜΑΤΙΑ!
Πώς λειτουργεί το Web Scraping
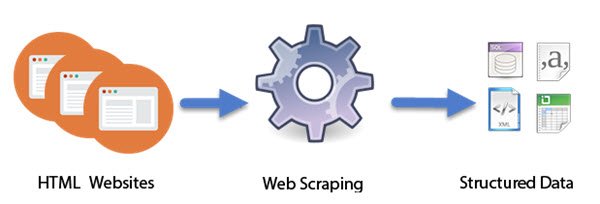
Τα(Computer) προγράμματα υπολογιστών που έχουν σχεδιαστεί ως Intelligent bot κάνουν τη δουλειά του Web Scraping . Σε αντίθεση με το scraping οθόνης, το οποίο αντιγράφει μόνο pixels που εμφανίζονται στην οθόνη, το web scraping εξάγει τον υποκείμενο κώδικα HTML και, μαζί του, τα δεδομένα που είναι αποθηκευμένα σε μια βάση δεδομένων. Η προσέγγιση έχει γίνει αρκετά δημοφιλής. Στην πραγματικότητα, θεωρείται ως μια από τις βασικές δεξιότητες που πρέπει να αποκτήσετε στον σημερινό ψηφιακό κόσμο. Έχει μερικές εξαιρετικές εφαρμογές στη συλλογή μεγάλων συνόλων δεδομένων, θεμελιώδεις για τεχνικές όπως-
- Big Data Analytics
- Μηχανική Μάθηση
- Τεχνητή νοημοσύνη(Artificial Intelligence)
Με την ταχεία επέκταση των ψηφιακών πληροφοριών, η πρόσβαση στα μεγάλα δεδομένα(Big Data) μέσω της προσέγγισης Web Scraping ή Web Data Extraction έχει γίνει πολύ πιο εύκολη. Τούτου λεχθέντος, το Web Scraping μπορεί να χρησιμοποιηθεί για ψηφιακές επιχειρήσεις που βασίζονται στη συλλογή δεδομένων και στις δύο, νόμιμες(Legitimate) ή παράνομες περιπτώσεις. Το πρώτο περιλαμβάνει Παραδείγματα ευεργετικής απόξεσης Ιστού(Benevolent Web Scraping Examples) ενώ το δεύτερο περιλαμβάνει παραδείγματα Κακόβουλης απόξεσης Ιστού(Malicious Web Scraping) .
Παραδείγματα καλοπροαίρετου Web Scraping
- Bot μηχανών αναζήτησης(Search) που ανιχνεύουν έναν ιστότοπο, αναλύουν το περιεχόμενό του για να ορίσουν μια κατάταξη με βάση ορισμένα ευρήματα, όπως το Google(Google) .
- Ιστότοποι σύγκρισης τιμών(Price) που αναπτύσσουν bots για αυτόματη ανάκτηση τιμών προϊόντων
- Εταιρείες έρευνας αγοράς(Market) που χρησιμοποιούν ξύστρες για εξαγωγή δεδομένων από τα μέσα κοινωνικής δικτύωσης (π.χ. για ανάλυση συναισθήματος, προσωπικές προτιμήσεις κ.λπ.).
Παραδείγματα κακόβουλης απόξεσης ιστού
Το Web Scraping(Web Scraping) για παράνομους σκοπούς μπορεί να προκαλέσει σοβαρές οικονομικές απώλειες εάν τα δεδομένα εξαχθούν χωρίς την άδεια των κατόχων του ιστότοπου. Οι δύο πιο συνηθισμένες περιπτώσεις χρήσης κακόβουλου Web Scraping(Malicious Web Scraping) είναι η απόξεση τιμών και η κλοπή περιεχομένου.
- Price Scraping – Τα bots Scraper επιθεωρούν ανταγωνιστικές βάσεις δεδομένων επιχειρήσεων για να αποκτήσουν πρόσβαση σε πληροφορίες τιμολόγησης, να υποτιμήσουν τους ανταγωνιστές και να ενισχύσουν τις πωλήσεις.
- Κλοπή περιεχομένου(Content Theft) – Αυτή η παράνομη δραστηριότητα περιλαμβάνει κλοπή περιεχομένου μεγάλης κλίμακας από έναν ιστότοπο-στόχο. Οι τυπικοί στόχοι περιλαμβάνουν κυρίως διαδικτυακούς καταλόγους προϊόντων και ιστότοπους που βασίζονται σε ψηφιακό περιεχόμενο για την προώθηση των επιχειρήσεων.
Ελπίζω αυτό να βοηθήσει!

About the author
Είμαι επιστήμονας πληροφορικής με πάνω από 10 χρόνια εμπειρίας στην ανάπτυξη λογισμικού και την ασφάλεια. Έχω έντονο ενδιαφέρον για τα παιχνίδια Firefox, Chrome και Xbox. Συγκεκριμένα, με ενδιαφέρει ιδιαίτερα πώς να βεβαιωθώ ότι ο κώδικάς μου είναι ασφαλής και αποτελεσματικός.
Related posts
Δεν υπάρχει δυνατότητα σύνδεσης στο Διαδίκτυο, αλλά εμφανίζεται ως Συνδεδεμένος στον Ιστό
Τι είναι το Bitcoin, το ψηφιακό νόμισμα
Τι συμβαίνει στους διαδικτυακούς σας λογαριασμούς όταν πεθάνετε: Διαχείριση ψηφιακών περιουσιακών στοιχείων
Τι είναι το Dark Web ή το Deep Web; Τρόπος πρόσβασης και προφυλάξεις.
Οφέλη από τη λήψη Digital Detox και πώς να το κάνετε
Το καλύτερο δωρεάν λογισμικό Internet Security Suite για υπολογιστή Windows 11/10
Λίστα με το Καλύτερο Δωρεάν Λογισμικό Απορρήτου Διαδικτύου και Προϊόντα για Windows 11/10
10 Παραδείγματα Web 3.0: Είναι το μέλλον του Διαδικτύου;
Ηλεκτρονικό έγκλημα και η ταξινόμηση του - Οργανωμένο και μη
Το εικονίδιο δικτύου λέει Δεν υπάρχει πρόσβαση στο διαδίκτυο, αλλά είμαι συνδεδεμένος
Οι εφαρμογές Edge και Store δεν συνδέονται στο Διαδίκτυο - Σφάλμα 80072EFD
Ελέγξτε εάν η σύνδεσή σας στο Διαδίκτυο έχει τη δυνατότητα ροής περιεχομένου 4K
Το TACHYON Internet Security είναι μια αξιοπρεπής εναλλακτική λύση σε άλλα δωρεάν εργαλεία
Σε ποιον ανήκει το Διαδίκτυο; Επεξήγηση της Αρχιτεκτονικής Ιστού
Πού είναι ο Άγιος Βασίλης αυτή τη στιγμή; Οι ιστότοποι παρακολούθησης του Άγιου Βασίλη θα σας βοηθήσουν
Μπορεί να καταρρεύσει ολόκληρο το Διαδίκτυο; Μπορεί η υπερβολική χρήση να καταρρίψει το Διαδίκτυο;
Γρήγορη μετεγκατάσταση από τον Internet Explorer στον Edge χρησιμοποιώντας αυτά τα εργαλεία
Άρθρο για την Ασφάλεια Διαδικτύου και συμβουλές για χρήστες Windows
Τι είναι τα Parked Domains και τα Sinkhole Domains;
Δεν μπορείτε να συνδεθείτε στο Διαδίκτυο; Δοκιμάστε το Complete Internet Repair Tool